Demystifying the Central Limit Theorem
Marbles to the Rescue: Making the Abstract Tangible
Taking More Samples
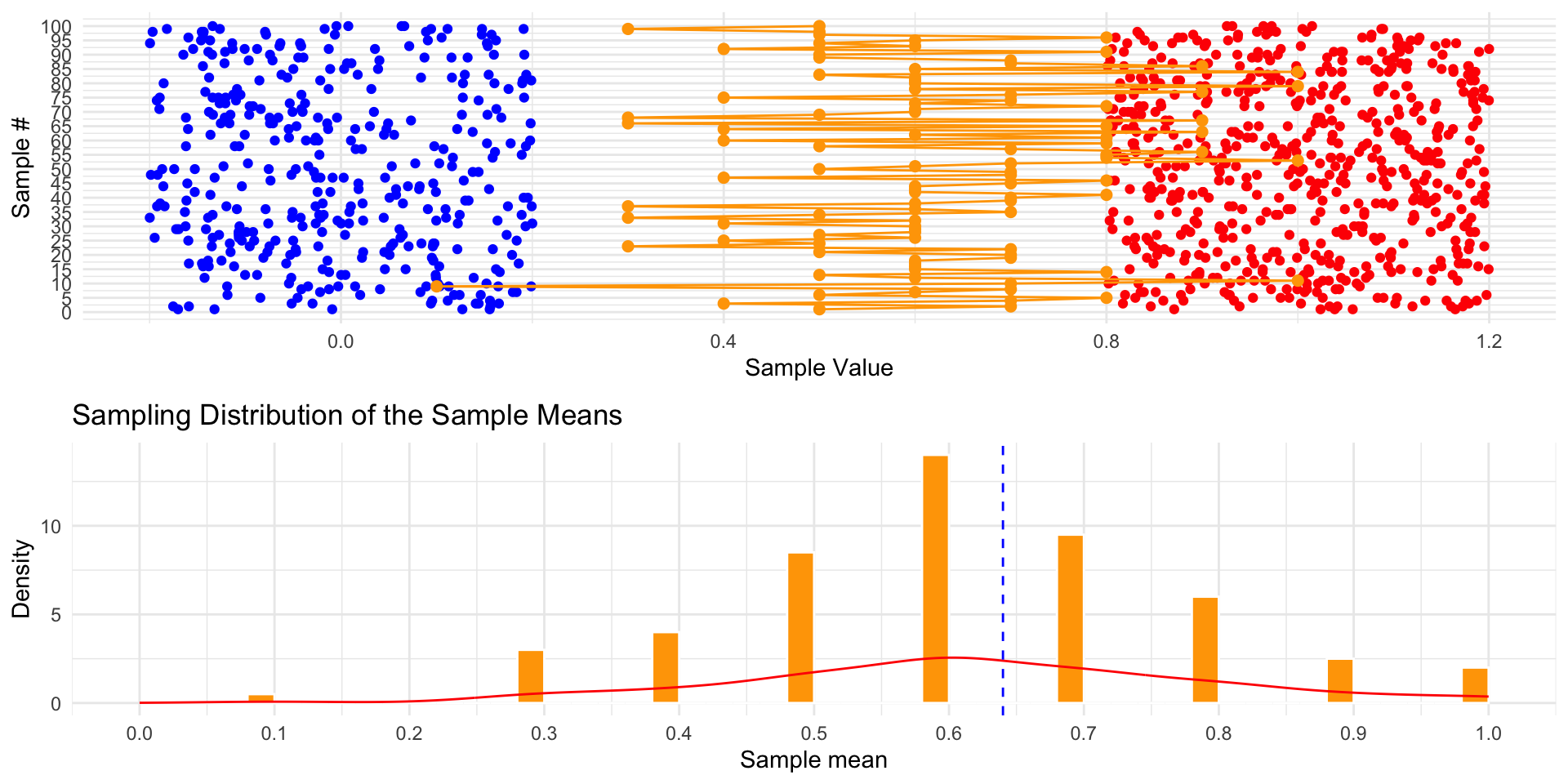
Increasing Sample Size to 20

Increasing Sample Size to 50
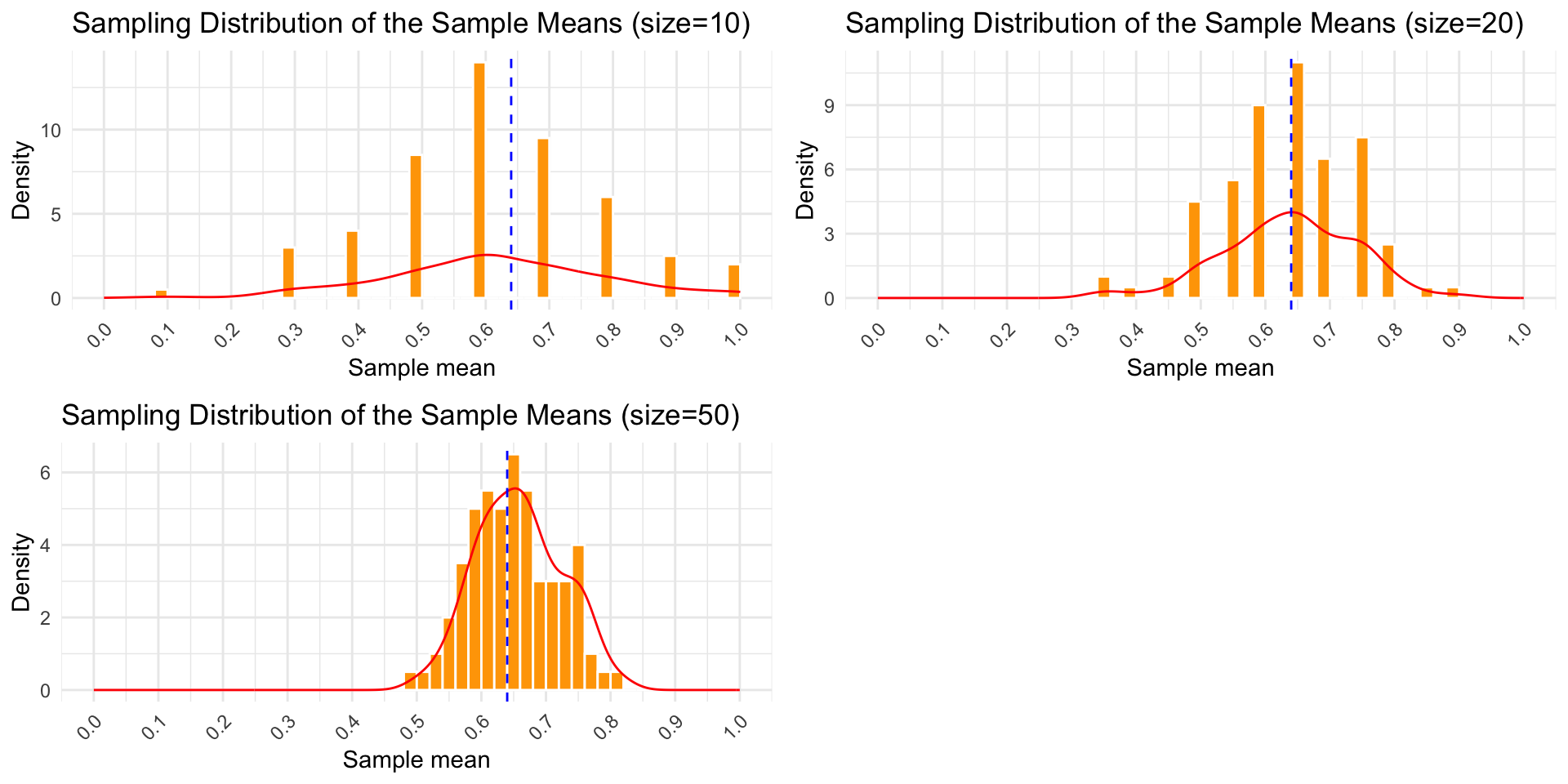
Increasing Sample Size to 100
Skewed Data
set.seed(42)
n = 1000
mean_log = log(30000)
sd_log = 1
salaries = rlnorm(n, meanlog = mean_log, sdlog = sd_log)
ggplot(data.frame(salaries), aes(x = salaries)) +
geom_histogram(bins = 50, fill = "blue", color = "black") +
geom_vline(xintercept = mean(salaries), color = "red", linewidth = 1) +
geom_text(aes(x = mean(salaries) * 2, y = 400, label = str_glue("{round(mean(salaries), 2)}")),
color = "red", size = 3) +
labs(title = "Salary Distribution", x = "Salary", y = "Count") +
theme_minimal()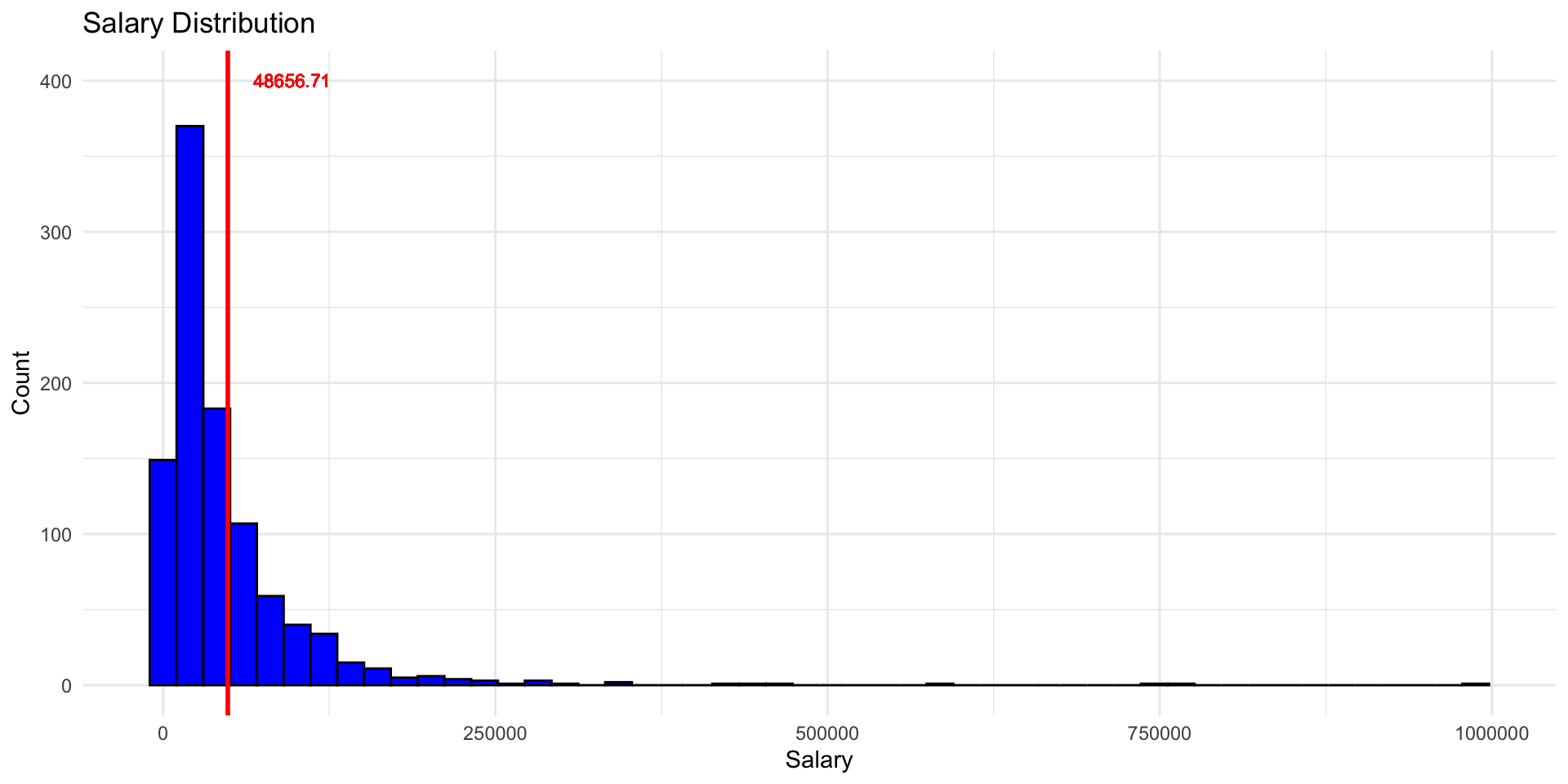
Skewed Data
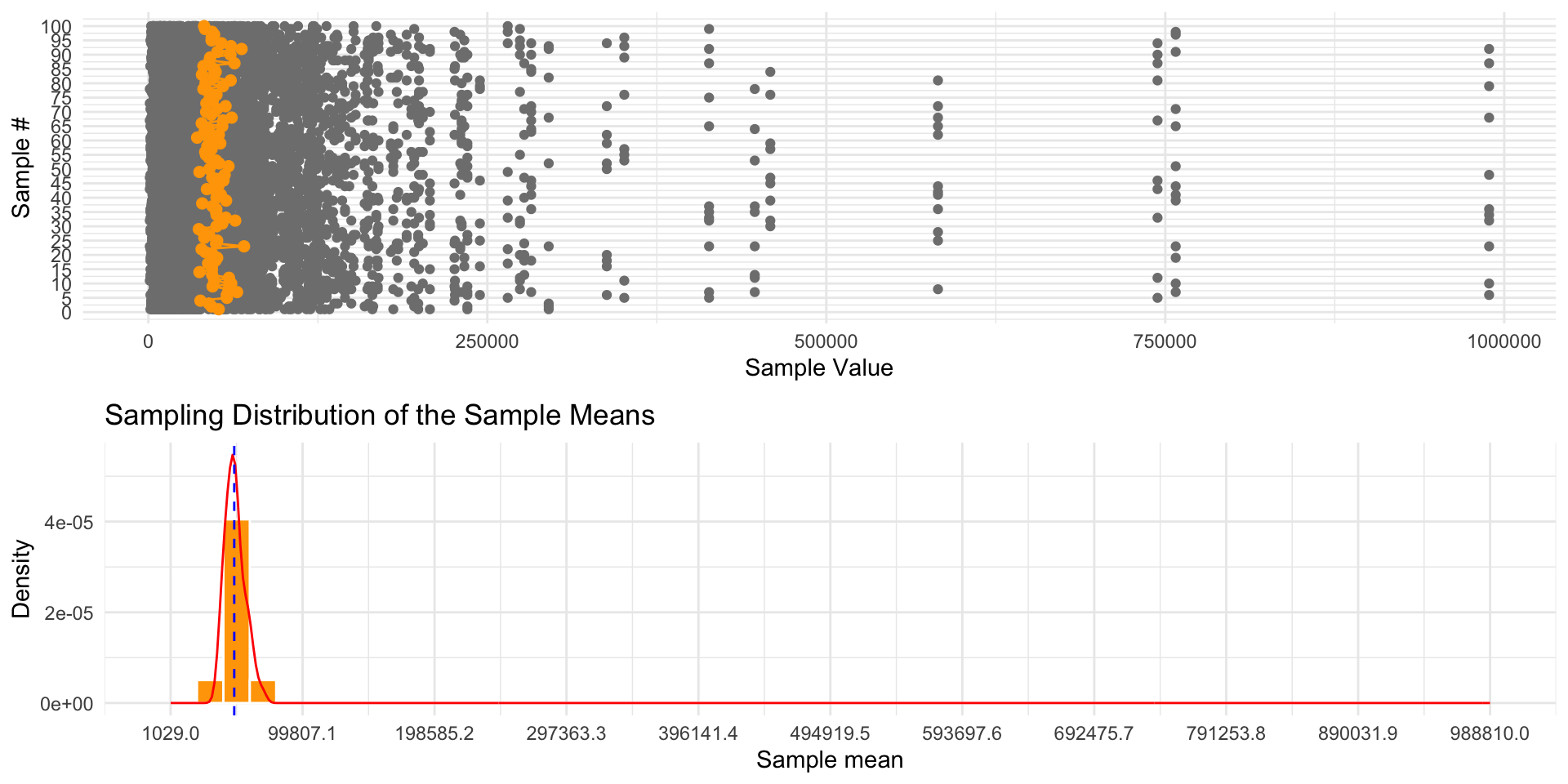
Key Insights
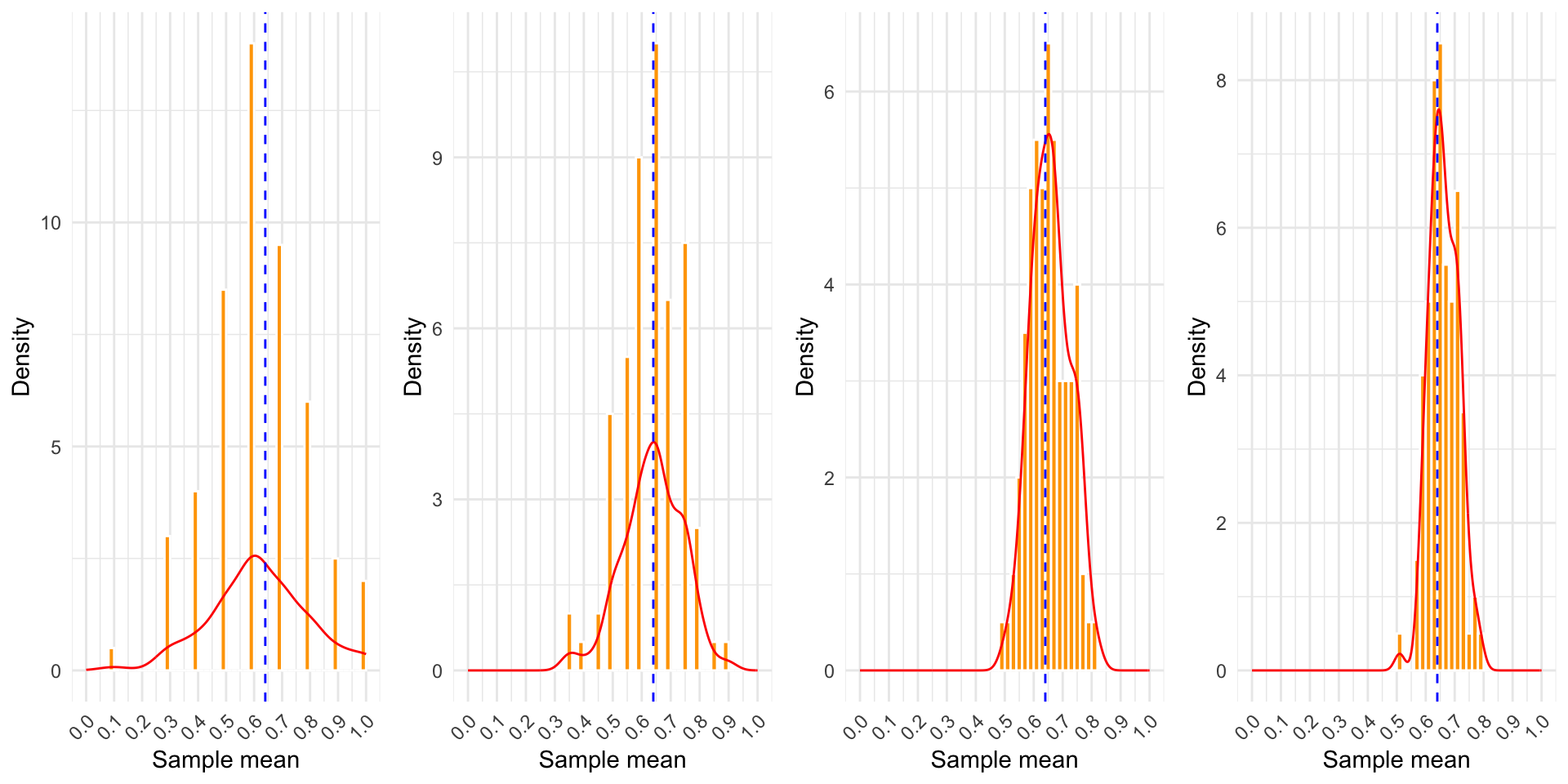
- Sample means cluster around the population mean
- Larger sample sizes decrease variability
- Distribution of sample means becomes more normal as size increases
- Works for any population distribution